Python - Llama.cpp GPU로 Windows 에서 구동하기
Windows에서 Llama.cpp 버전을 사용하는 것은 필자와 같이 Windows를 주로 사용하는 유저에게는 꼭 필요한 부분으로, 약간은 번거롭지만, 어렵지 않고 한번 해두면 계속 사용할 수 있기 때문에 여기에 정리해 둔다.

1. Git 설치
Github과 같은 레포스토리지를 활용하기 위해서 설치해야 한다. 기본옵션으로 설치하자.

2. Conda 설치
별다른 옵션을 선택할 필요는 없다. 기본옵션으로 설치하자.


설치시 기본 옵션으로 설치하자.

3. Visual Studio - C++를 사용한 데스크톱 개발 설치
Windows용 Visual Studio C/C++ IDE 및 컴파일러
윈도우에서는 cmake, nmake와 같은 추가 명령어를 이용해서 llama-cpp-python를 구성해야 하기 때문에 아래 버전도 설치해야 정상적으로 동작한다.

4. CUDAtoolkit, cuDNN 설치
CUDA 역시 설치가 많이 쉬워졌다고 할 수 있다. 대부분 기본 옵션으로도 잘 동작하므로 설치한 위치만 잘 기억하고 기본 옵션을 이용해서 설치하도록 하자. CUDA 도구 설치시 Visual Studio Integration 옵션이 체크되어 있는지만 잘 확인하면 된다.(기본적으로 체크되어 있음)
CUDA Toolkit 12.9 Update 1 Downloads | NVIDIA Developer


다음으로 cuDNN을 설치하도록 하자. 다운로드후 기본값으로 설치하면 끝이다.

이를 설치를 진행하고 나면, 마지막으로 환경 변수 화면을 열어서 CUDAtoolkit 의 bin, include, lib 폴더를 환경을 Path에 추가해주면 사용이 전역적으로 사용할 수 있기 때문에 편리하게 사용할 수 있다. 추가해주도록 하자.
그리고 이때 PC를 재부팅해주는 것을 추천한다.


이렇게 다 설치를 잘 했다면, Anaconda Powershell Prompt 혹은 Anaconda Prompt 를 실행하도록 하자.

실행하고 git이 잘 동작하는지 확인해보면 특별한 문제가 없는 이상 아래와 같이 git 명령이 이용할 수 있을것이다.

5. Conda 환경 설정하기
가장먼저 할일은 우리가 구성할 LLM 환경을 만드는 것이다.
아래와 같이 환경 구성을 진행하자. condallama 라는 환경을 만드는 건데, 현재 최신버전의 Python을 사용해도 좋지만, 호환성등을 고려해 필자는 3.11을 사용했다.
conda create -n condallama python=3.11위 명령을 실행하면, conda가 Python 3.11 버전과 함께 가상 환경에 필요한 라이브러리들을 구축해 준다.
이후 아래 명령으로 가상환경을 활성화해서 독립된 환경에서 llama.cpp를 구동할 준비를 해보자.
conda activate condallama정상적으로 잘 구동되었다면, 아래와 같이 프롬프트 가장 앞쪽에 소괄호에 condallama라고 표시가 될 것이다.
이제 격리된 환경이니 편하게 설정할 수 있다.
이상태에서 https://github.com/abetlen/llama-cpp-python 의 레포에서 다운로드를 진행하도록 하자.
git clone --recurse-submodules https://github.com/abetlen/llama-cpp-python.git잘 다운로드가 되었다면, 해당 디렉토리로 이동한다.
cd llama-cpp-python6. llama-cpp 빌드
이제 거희 마무리 단계라고 할 수 있다. 패키지 빌드를 위해서 필요한 라이브러리 cmake와 ninja를 pip 명령을 이용해서 다운로드하도록 하자.
pip install cmake ninja빌드하기전에 우리가 설치한 CUDA의 경로를 CUDA_HOME으로 지정해 줘야한다. 자신이 다운로드한 버전을 확인하고 해당 경로를 기입하도록 하자. 이 작업을 해야만 GPU를 활용할 수 있게 된다.
set CUDA_HOME="C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.9"그리고 설치전에 아래 환경 변수들도 등록이 되어 있는지 확인하도록 하자.
시작메뉴에서 환경 변수 라고 검색하면 바로 갈 수 있다.
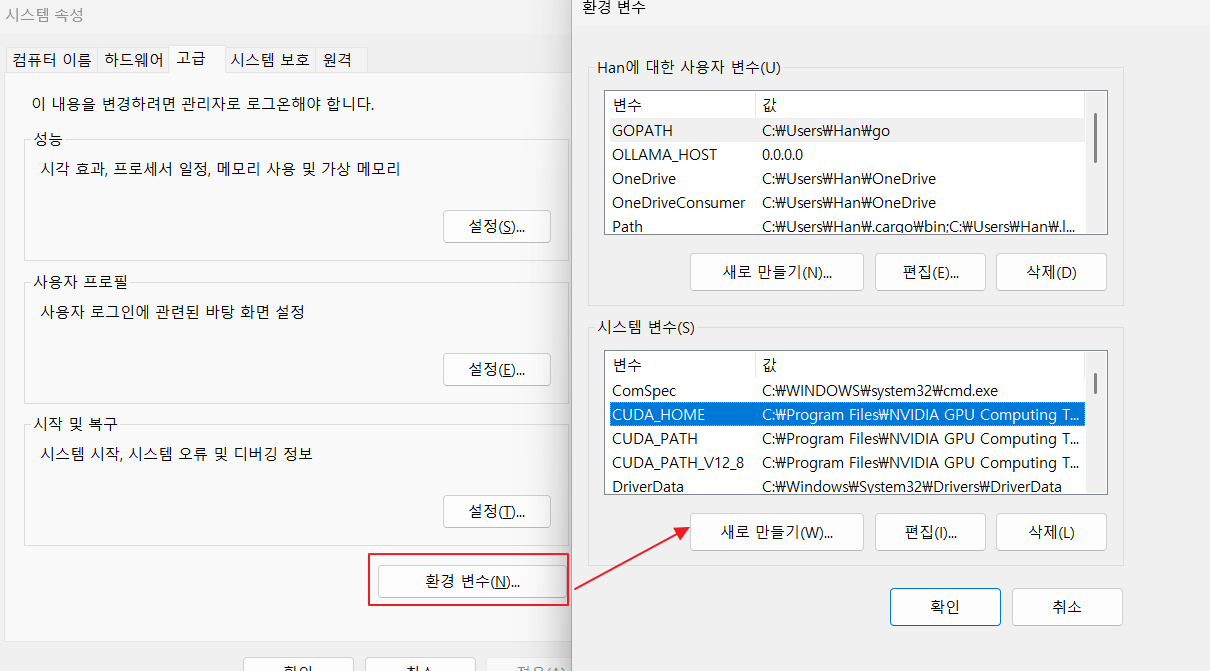
등록이 되어있지 않다면 등록하자.
set CUDA_HOME="C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.9"
set PATH=%CUDA_HOME%\bin;%PATH%
set PATH=%CUDA_HOME%\libnvvp;%PATH%
set FORCE_CMAKE=1
set CMAKE_ARGS=-DGGML_CUDA=on
set GGML_CUDA=1이제 준비가 완료되었다. 설치를 시작하자.
pip install . --upgrade --force-reinstall --no-cache-dir정상적으로 설치된다면, 10-20분정도 걸리기 때문에 커피한잔 하던 게임을 하던 시간을 보내도록 하자.
만약 작업이 빨리 끝이났다면, CUDA 설정이 잘 진행되지 않았을 가능성이 높다. 천천히 빼먹은게 없는지, 아니면 conda 가상환경부터 새로 하거나 설치를 다시 하는 방법을 추천한다.
7. CUDA 확인
Pytorch를 설치하는데, pytorch-cuda=12.9은 앞서 nvcc --version을 통해서 화면에 나타나는 버전 정보를 통해서 입력하면 된다.

8. 동작 확인
잘 동작하는지 확인을 위해서pip install을 통해서 torch를 설치하도록 하자. 이후 python 명령을 사용해서 확인해보도록 하자.
pythontorch를 통해서 GPU 사용이 가능한 상태인지 확인하면 끝이다. torch는 pip install pytorch 로 설치할 수 있다.
import torch
torch.cuda.is_available()만약 torch 입력시 필자와 같이 아래와 같은 OpenMP runtime 오류가 난다면, 아래 KMP_DUPLICATE_LIB_OK 를 활성화하여 임시적으로 해결할 수 있다.
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
(condallama) PS C:\Users\Han\llama-cpp-python> OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.

Llama.cpp 실행
from llama_cpp import Llama
model_path=r"C:\Users\Han\llama-32b-q4_k_m.gguf"
model = Llama(model_path=model_path, n_gpu_layers=20)n_gpu_layers=은 모델의 모든 레이어를 GPU로 오프로드하라는 의미로, -1은 GPU 메모리에 전체를 올리는 것을 위미한다.
GPU 메모리별 추천되는 수는 다음과 같다.


| GPU 메모리 | gpu_layers |
| 4GB | 10~15 |
| 8GB | 20~30 |
| 12GB | 30~40 |
| 24GB 이상 | -1 가능 (전체 오프로드) |
잘동작 하는 것을 확인했기 때문에, 이제 테스트를 위한 테슽 환경을 주피터 노트북을 설치하도록 하자.
conda install -c conda-forge jupyterlab설치가 마무리 되었다면, jupyter lab 을 통해 실행할 수 있다.

전체 예제 코드는 다음과 같다.
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import torch
from llama_cpp import Llama
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = 'cpu'
# 모델 로드
model_path = r"Your model patch/F.gguf"
model = Llama(model_path=model_path, n_ctx=512, n_batch=512, gpu_layers=60, device=device)
# 대화 히스토리 저장용 리스트
conversation = []
def chat_with_model(prompt):
# 지금까지의 대화를 이어붙이기
full_prompt = "\n".join(conversation) + f"\nUser: {prompt}\nAssistant:"
output = model(full_prompt, max_tokens=200)
response = output['choices'][0]['text'].strip()
# 대화 내용 추가
conversation.append(f"User: {prompt}")
conversation.append(f"Assistant: {response}")
print(response)
# 예시 사용
chat_with_model("안녕? 오늘 기분 어때?")
마치며
만약 정상적으로 동작하지 않는다면, 환경 변수 설정등이 잘 되지 않았을 경우이다. 다시 llama.cpp 설치 하는 부분을 반복해보고 체크하도록 하자.
더욱 간편하게 사용하기에는 winget install llama.cpp 를 이용해서 설치하는 방법도 있기 때문에 자신이 이용하고자 하는 목적에 맞게 설치하도록 하자.
winget install llama.cpp