오늘은 최근에 특정 문자열 갯수를 넘어가는 글에 대해서 조금 더 이쁘게 잘라 낼 수 있을까에 대한 고민하던 부분중에 개발을 진행한 부분에 대한 내용이다.
고민한 내용은 간단하다. \n 기준으로 문자열을 자르고 싶은데, \n을 기준으로 자르자니 너무 많이 문자열이 잘라지므로 이를 가장 알맞은 길이를 대입하여 자르고 싶었다. 그래서 생각한 규칙은 다음과 같다.
특정 길이 기반으로 문자열을 자른다.
만약 원하는 구분자가 해당 특정 길이 내에 있다면, 특정 길이를 안에 있는 구분자를 이용하여 자른다.
원하는 구분자가 특정 길이에 여러개 있다면 최대한의 크기를 유지 할 수 있었으면 한다.
원하는 구분자가 없는 경우에는 최대 크기로 자른다.
조건은 위 4가지 인데 실제 코드를 작성해 보니 생각보다 고려해야 할 포인트가 많았다.
잘라내는 문자열 함수에 대한 이해가 필요하다.
Python에서는 문자열 값에 중괄호 []를 이용하여, 시작 인덱스와 마지막 인덱스를 사용하여 쉽게 사용이 가능하다.=
msg = hello
msg = msg[0:1]
msg만약 hello 라는 글자가 있다면, 0부터 시작하여 1이 h를 의미 한다. 만약 2를 적으면 he 라는 값이 남게 된다.

다음으로는 원하는 문자열을 찾는 방법이다. 이는 쉽게 진행할 수 있는데, 메세지를 하나씩 나누어 전달하는 enumerate가 제격이다. enumerate를 사용하면 2가지 인자로 값을 전달하는데 첫번째 값이 문자열 위치, 두번째 값이 문자열이다.
아래와 같이 사용하면 현재 문자열의 위치를 쉽게 확인이 가능하다.
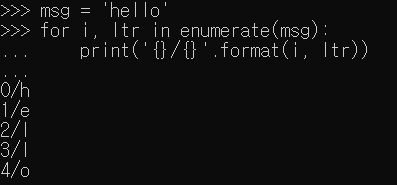
이를 사용하여 아래와 같은 코드를 통해 원하는 구분자를 기준으로 문자열을 원하는 크기에 최대한 우선하는 문자열을 만들어주는 코드를 작성하였다.
def Split_Word(msg, findstr, split_lengh):
index_msg = [i for i, ltr in enumerate(msg) if ltr == findstr]
print('현재 구분자 갯수: '+str(len(index_msg)))
sub_index = len(findstr)
max_index = len(msg)
sub = (split_lengh * 10.0 / 100.0)
sub_frist_x = round(sub)
frist_x = split_lengh - sub_frist_x
end_x = split_lengh
frist_index = 0
lastvaluse = 0
reslist = []
for x_index in index_msg:
splitvalue = 0
if x_index > frist_x and x_index < end_x:
splitvalue = x_index
elif x_index > end_x:
splitvalue = lastvaluse
lastvaluse = x_index
else:
lastvaluse = x_index
if splitvalue != 0:
res=msg[frist_index:splitvalue]
if res:
reslist.append(res)
frist_index = splitvalue+sub_index
frist_x = splitvalue+split_lengh - sub_frist_x
if (end_x+split_lengh) < max_index:
end_x = splitvalue+split_lengh
else:
end_x = max_index
return reslist
o_msg = 'hello\nhello\nhellonhellonhello\nhellonhellonhello\n\nhello\nhellonhellonhello\nhellonhellonhello\nhello\nhellonhellonhello\nhellonhellonhello\nhello\nnhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\nhellonhellonhello\n'
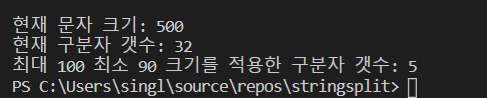
print('현재 문자 크기: '+str(len(o_msg)))
res = Split_Word(o_msg, '\n', 100)
print('최대 100 최소 90 크기를 적용한 구분자 갯수: '+str(len(res)))
주요 비교문에 대해서 알아보면,
if x_index > frist_x and x_index < end_x:
splitvalue = x_index가장 먼저 나타나는 위 코드는 최소 조건 길이와 최대 길이 안에 값이 존재하는지를 확인하는 코드이다. 이 코드를 통해서 기본적으로 우리가 원하는 위치에 구분자가 있는지를 확인하게 된다.
만약 넘어가는 값이라면, 마지막 값을 저장해두는 두어 혹시 다음 비교시에 맞는 값이 없어 마지막 값을 사용해야 하는 상황을 위해 lastvaluse = x_index 를 통해서 마지막 값을 저장해 둔다.
그리고 맞는 값이 없는지를 아래 코드를 통해 비교한다.
elif x_index > end_x:이 조건으로 인해 사이 값인 경우에는 이 값을 이용한다. 만약 값이 넘어간다면, 한번 더 마지막으로 마지막에 저장된 값은 사이 값인지 if lastvaluse > end_x:를 통해서 보게 된다.
예제의 코드를 실행하면 다음과 같은 결과를 얻을 수 있다.
몇가지 더 수정할 수 있는 부분이 있지만 여기까지 정리해 보고 다양한 의견이나 아이디어는 댓글로 남겨주기 바란다.

